What is "aaaaigz0...my4xmda="?
Since I launched this website, I have received many requests to help decode or repair various Base64 values. So the idea came up to create the Repair Tool, which is able to fix malformed strings in automatic mode. Nevertheless, that tool is not a silver bullet and it cannot repair all strings. Therefore, it is not surprising that people still contact me to help them. Well, I am not an almighty magician, so I need the help of others. Maybe you can help me solve a new puzzle?
The Problem: We have an “almost valid” Base64 string in which all letters are lowercase. Because of this, we cannot decode the string to get the original data.
Known Details: It seems this string is a MP4 v1 video file, that have the header 00 00 00 20 66 74 79 70 69 73 6f 6d. Most likely this is a stub file used for tests and has a very small resolution (something like 2×2).
The objective: Find out the original string so that we can decode it using the Base64 Decode tool and play the obtained file using a regular video player. If you know any details about this string or have the original string, please submit a comment or contact me. Feel free to submit even the craziest ideas. Even the smallest clues can help me solve the puzzle. Thank you!
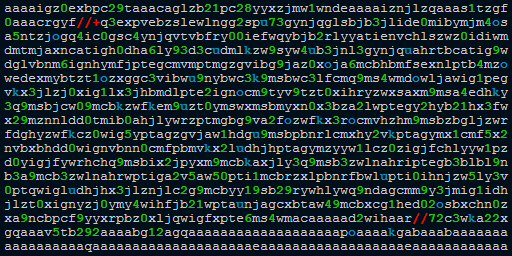
Malformed Base64: data:video/mp4;base64,aaaaigz0exbpc29taaacaglzb21pc28yyxzjmw1wndeaaaaiznjlzqaaas1tzgf0aaacrgyf//+q3expvebzslewlngg2spu73gynjqglsbjb3jlide0mibymjm4osa5ntzjogq4ic0gsc4ynjqvtvbfry00iefwqybjb2rlyyatienvchlszwz0idiwmdmtmjaxncatigh0dha6ly93d3cudmlkzw9syw4ub3jnl3gynjquahrtbcatig9wdglvbnm6ignhymfjptegcmvmptmgzgvibg9jaz0xoja6mcbhbmfsexnlptb4mzowedexmybtzt1ozxggc3vibwu9nybwc3k9msbwc3lfcmq9ms4wmdowljawig1pegvkx3jlzj0xig1lx3jhbmdlpte2ignocm9tyv9tzt0xihryzwxsaxm9msa4edhky3q9msbjcw09mcbkzwfkem9uzt0ymswxmsbmyxn0x3bza2lwptegy2hyb21hx3fwx29mznnldd0tmib0ahjlywrzptmgbg9va2fozwfkx3rocmvhzhm9msbzbgljzwrfdghyzwfkcz0wig5yptagzgvjaw1hdgu9msbpbnrlcmxhy2vkptagymx1cmf5x2nvbxbhdd0wignvbnn0cmfpbmvkx2ludhjhptagymzyyw1lcz0zigjfchlyyw1pzd0yigjfywrhchq9msbix2jpyxm9mcbkaxjly3q9msb3zwlnahriptegb3blbl9nb3a9mcb3zwlnahrwptiga2v5aw50pti1mcbrzxlpbnrfbwlupti0ihnjzw5ly3v0ptqwigludhjhx3jlznjlc2g9mcbyy19sb29rywhlywq9ndagcmm9y3jmig1idhjlzt0xignyzj0ymy4wihfjb21wptaunjagcxbtaw49mcbxcg1hed02osbxchn0zxa9ncbpcf9yyxrpbz0xljqwigfxpte6ms4wmacaaaaad2wihaar//72c3wka22xgqaaav5tb292aaaabg12agqaaaaaaaaaaaaaaaaaaapoaaaakgabaaabaaaaaaaaaaaaaaaaaqaaaaaaaaaaaaaaaaaaaaeaaaaaaaaaaaaaaaaaaeaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaacaaackhryywsaaabcdgtozaaaaamaaaaaaaaaaaaaaaeaaaaaaaaakgaaaaaaaaaaaaaaaaaaaaaaaqaaaaaaaaaaaaaaaaaaaaeaaaaaaaaaaaaaaaaaaeaaaaaacaaaaagaaaaaacrlzhrzaaaahgvsc3qaaaaaaaaaaqaaacoaaaaaaaeaaaaaaabtzglhaaaaig1kagqaaaaaaaaaaaaaaaaaadaaaaacabxhaaaaaaatagrscgaaaaaaaaaadmlkzqaaaaaaaaaaaaaaafzpzgvvsgfuzgxlcgaaaaflbwluzgaaabr2bwhkaaaaaqaaaaaaaaaaaaaajgrpbmyaaaaczhjlzgaaaaaaaaabaaaadhvybcaaaaabaaabc3n0ymwaaacnc3rzzaaaaaaaaaabaaaal2f2yzeaaaaaaaaaaqaaaaaaaaaaaaaaaaaaaaaacaaiaegaaabiaaaaaaaaaaeaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaay//8aaaaxyxzjqwfkaar/4qayz2qacqzzx5zcbeaaaamaqaaadapeiwwaaqagaovjyylaaaaaehbhc3aaaaabaaaaaqaaabhzdhrzaaaaaaaaaaeaaaabaaacaaaaabxzdhnjaaaaaaaaaaeaaaabaaaaaqaaaaeaaaauc3rzegaaaaaaaalfaaaaaqaaabrzdgnvaaaaaaaaaaeaaaawaaaaynvkdgeaaababwv0yqaaaaaaaaahagrscgaaaaaaaaaabwrpcmfwcgwaaaaaaaaaaaaaaaatawxzdaaaacwpdg9vaaaahwrhdgeaaaabaaaaaexhdmy1ny44my4xmda=
By the way, I think to develop a brute-force tool that will change each letter to uppercase until it will find the right file format, but this method may lead to a lot of errors. Anyway, I will update the post as soon as I find out or receive new details.
 Validate Base64 using Notepad++
Validate Base64 using Notepad++ Base64 encryption is a lie
Base64 encryption is a lie Launched the Base64 Repair Tool
Launched the Base64 Repair Tool
Comments (87)
I hope you enjoy this discussion. In any case, I ask you to join it.
Hello,
Very interesting subject!
I wanted to know if your work had been successful with this type of decoding?
Indeed, I am interested in the "repair" of files encoded in base64, whose base64 would have been put in all upper case (or lowercase).
My ultimate goal is to analyze compression rates (zlib / gzip) between a base64, a base64-capital or a base64-lowercase.
Only the problem is: "how to find the initial case of base64 to be able to decode it?".
Knowing that encoded files can be of any type, but initially only flat text files (which may contain alpha-numeric characters, symbols, spaces / line breaks and accented characters).
Your help would be very precious to me!
Thanking you for your interest and your work,
Excellent day,
I am very glad that I am not the only one who is interested in solving this. Unfortunately, brute-forcing gives a lot of false positives even if the original data has a strict format (something like XML) and contains only a limited character set.
For example, the string
phhtbd5cyxnlnjqur3vydtwveg1spg==is the lowered Base64 value of<xml>Base64.Guru</xml>. Trying to brute-force all “permutations” of the malformed string and filter results that contain valid XML and characters from[\x20-\x7E], it will find 8 suitable values:PHhtbD5CYXNLNjQuR3VYdTwveG1sPg== | <xml>BasK64.GuXu</xml>PHhtbD5CYXNLNjQuR3VydTwveG1sPg== | <xml>BasK64.Guru</xml>
PHhtbD5CYXNlNjQuR3VYdTwveG1sPg== | <xml>Base64.GuXu</xml>
PHhtbD5CYXNlNjQuR3VydTwveG1sPg== | <xml>Base64.Guru</xml>
PHhtbD5cYXNLNjQuR3VYdTwveG1sPg== | <xml>\asK64.GuXu</xml>
PHhtbD5cYXNLNjQuR3VydTwveG1sPg== | <xml>\asK64.Guru</xml>
PHhtbD5cYXNlNjQuR3VYdTwveG1sPg== | <xml>\ase64.GuXu</xml>
PHhtbD5cYXNlNjQuR3VydTwveG1sPg== | <xml>\ase64.Guru</xml>
Now imagine a larger malformed string that contains binary values or a wider range of characters (e.g., XML supports UTF-8). For example, just by extending the charset to US-ASCII (
[\x00-\x7F]) the same example will return 16 suitable values.So, I think that only a desperate person will try to restore the original data in a such way :)
Best wishes,
Victor
for those of you who don't want to read this,dont open the 2nd compress,for those of you who do,read away!hello,victor(admin)
A very Interesting subject!
and a relatively decent idea,there is a big con to the idea you have though,the amount of time to brute-force all permutations(or logical ones only) will at some points take hours or days,maybe even weeks(depends length of string)
Now,that said,i do have a unique idea that might hold better than most
Due to how Base64 works,you in almost all cases,have to brute-force the data,but the strategy you use will have effects on speed and accuracy
Now,the version i have thought of required some precise knowledge,so i had to look at the Base64 Encode Algorithim,to see where most corruption issues arise,what they can be considered as,and find a relatively exact method that always finds data
So far,here's what i've found
When you encode to base 64,you have to follow this method:
Text,Enc. to binary,read as 6-bit,add 00 to front of 6-bit,Dec. to b64 indice,Dec. to text
Now,step 3 is where the issues arise,hmmm...how shall i explain this...an example should suffice.
(00 used as filler)
Example:
Binary:
RRRRRRRR GGGGGGGG BBBBBBBB
Read as 6-bit:
RRRRRR RRGGGG GGGGBB BBBBBB
notice how the binary merges(case sensitivity),this then happens when the the string is corrupted:
When 6-bit corrupts:
YYYYYY YYRRRR RRRRGG GGGGGG GGBBBB BBBB00
This becomes random text(mojibake)and has multipue forms,like this:
2nd form:
XXXXXX XXYYYY YYYYRR RRRRRR GGGGGG GGBBBB BBBB00
3rd form:
XXXXXX XXYYYY YYYYZZ ZZZZZZ RRRRRR RRGGGG GGGGBB BBBBBB
Now,we also have versions where the data is intact in places,corrupted in others,etc. etc. etc.
So,in essence,corruption is deemable as original text,just shifted around,so...technically...all we need is a binary shift reader
Essentially a reader that shifts its starting point in the 6-bit before decode,eventually,you find all the data,can reprint it as time goes on,or pinpoint issue 6-bit bytes to remove from data
Now,metadata is a essential part to use for finding needed data(wether it is HTML,XML,HTTP links,etc.)
As a final note,not all data is going to be the same,there will be differences across all forms(/n in mime,for example) that have to be interpreted,therefore,i'd suggest a customizable lookup table for ppl to add data to for speedup of 'decorruption'*(*unshifting) of data.
Best wishes,Hey
well,thats a good reason there on why your supposed to look at all processes of something first...
So,just learned that no matter how many letters are read by a parser,the b64 indices (technically) prevent data corruption being one-way(still looking into the details rn)
hmmm...seems even the indices arent perfect...makes sense...if the binary is shifted then the data is always going to be corrupted requiring human intervention to find the corruption point(s)...yeah...seems like the binary shift reader is the best option...hmmm...wait...yeah...thats a possibility...so i i decided to look at 123's statement & then when i realized the shift in letters i realized the corruption was only partially there bc of it being treated case insensitively...so i decided to check the uppercase version & found rough areas needing capitals to be read via hex dump section here,so i decided then since case alteration was the issue bc of binary swaps b4 decoding to bc i didnt have energy to run through the whole string randomcase both versions alot & found several chunks in this thing...ftyp,isom,iso2,avc1,mp41,free was after the headers,found a spot that had codec in it,also think i found a odd link in it too...videolog org?,old device compatibility,either bluray compat or blurr_level?,found curl ref! i think?,has a ^moov atom in it for sure,was before repititious i's & h's...possible timeframes,...uhh...stsg/stsd/stbl?,x264 somewhere in it,step=4,lookahead,e=5(?),a number chunk like x.x.x.x?,avcC or avi points?...idr seeing mdat or mhvd in this but could be bc i was unlucky w randomcasing...was uning unit conversion info...which managed the permutations of admins examples but w at least 2 or so extras but unlikely to pop up new ones...in general it was just a random why not push this further?,see where it goes?...didnt peice this together unfortunately...so these are somewhere in the corruption just not known where...try dealing w it later...see what i can get...why Base64 is not given as it is image?
The Game.Good code service I love
essentially,the 6-bit data has to be shifted untill the string is decorrupted...but it is a feat to know what parts of the string are original data in videos or not(the part thats random symbols or nonexistant letters,emojis,etc.)therefore it would essentially be decrypting by brute-force to find original video data to find the sound as wellBefore:
dsagfdshdjfanjsd43agaaaaaaaaaaaaaa
after:
dsagfdshdjfanjsd43agAAAAAAAAAAAAAA
s/Good luck/Good luck, everyone/I'm too quick with sending posts before proofreading them.
for anyone that has had the pleasure of writing/reading metadata to/from files (especially ID3 tags, EXIF data, IPTC data, etc) will tell you how easy it is to corrupt files with software that although claims to support, does not actually or fully support said metadata formats.
what I propose is that although an audio/video/image file might be readable and renders to a point that appears to be "OK"; the file and/or region of the file could have been completely corrupted by metadata software (or perhaps even with the use of steganography).
image files (album covers, for example) can be embedded into media files.
I am not an expert in encoding/decoding base64 though do imagine some consideration would need to be given to regions of files which could be corrupted (as previously mentioned) but could still be readable, opened and rendered correctly.
if I may suggest that perhaps an attempt to base64 encode/decode a file both with and without associated metadata; what discernible differences there are and perhaps from there a method could be developed to first isolate the metadata so that it can be separated from the media content itself.
an option could be added to your base64 tool that allows encoding/decoding with or without metadata.
this way the file format container, headers, the media data, and the metadata could be processed independently.
in the past I have found this tool very useful;
https://exiftool.org/anyway, just a thought -- I was only here to base64 encode a wave file from the game Mario released on Super Nintendo (hehe).
very interesting post and puzzle! caught my eye.
The encode & decode were very useful for HTML programming, especially the "data url", so simple that I would be able to use it on any device, even with bad internet connections.
I was just wondering if there's a specific reason that you created this site, cause I love it!
before: aaaaigz0exbpc29taaacaglzb21pc28yyxzjmw1wndeaaaaiznjlzqaaa
after: AAAAIGZ0eXBpc29tAAACAGlzb21pc28yYXZjMW1wNDEAAAAIZnJlZQAAA
and
before: 4xmda=
after: 4xMDA=
source: https://jsfiddle.net/skibulk/kcwpsu2q/latest/
theory),but i dont have nearly enough in-depth knowledge to give one that helps point us in the right direction if we're doing
this,but,if the admin wants the rough layout
of it,i am willing to put it here
AAAAhow
was
your
day
...I might have searched the filename that 123 found in Google search and I came across a 2ppl conversation on this...I can go and find it for you if you like?
ZnR5cGlzb21pc29taXNvMmF2YzFtcDQxZnJlZQ==
aHR0cHM6Ly9tLnlvdXR1YmUuY29tL3dhdGNoP3Y9eGJVenRZRnB5Y2s=
watch it,now,someone called jumpjack happened to say in the end of the forum(which was on 09/22/2010 at 1:23pm)"
sorry for digging up such an ancient thread, but I have [the] same problem, and I cannot figure out which program was used to produce my MP4 file, as it is created by an EMTEC N100 digital recorder!",now,I did some searching on the company name,looked at the company profile, and found out that the release date of a emtec n100 digital recorder(assuming that release of DVD recordable range is when this was made) was,supposedly around...1999(meaning,1999-2024 is 25 yrs ago [geez,thats ancient]),so,with that said,I'm not sure that even if this embedded data gets decoded,the video aspect of this is able to be played,let alone the audio,as apperantly the n100 digital recorder is a Usb/SDCard video grabber,and ESPNSTIs file apperantly at a closer look into the code by a person called gotaserena said that it dosent look like a MP4 file at all,now someone else called bond said that the filename means that the MP4 dosent have a moov atom(essential for MP4 videos to play,apperantly) so,just going after the audio may be difficult for ours,I assume though,from the look of the name on ESPNSTIs file that this one,just like there's,contains MP41/42 data,which,as far as i can see,no form of video player can play the thing,hence why there's cant be played,meaning,this one we have here is probably not able to be played
oh,just the usual...comments spammed by sql injector ppl,amongst other wierd freaks,cryptic b64 chunks to?,a page of data with someones personal info in it,powershell.exe malware and dropoff url xss's...yeah...you name it...it is herewatch it,now,someone called jumpjack happened to say in the end of the forum(which was on 09/22/2010 at 1:23pm)"
sorry for digging up such an ancient thread, but I have [the] same problem, and I cannot figure out which program was used to produce my MP4 file, as it is created by an EMTEC N100 digital recorder!",now,I did some searching on the company name,looked at the company profile, and found out that the release date of a emtec n100 digital recorder(assuming that release of DVD recordable range is when this was made) was,supposedly around...1999(meaning,1999-2024 is 25 yrs ago [geez,thats ancient]),so,with that said,I'm not sure that even if this embedded data gets decoded,the video aspect of this is able to be played,let alone the audio,as apperantly the n100 digital recorder is a Usb/SDCard video grabber,and ESPNSTIs file apperantly at a closer look into the code by a person called gotaserena said that it dosent look like a MP4 file at all,now someone else called bond said that the filename means that the MP4 dosent have a moov atom(essential for MP4 videos to play,apperantly) so,just going after the audio may be difficult for ours,I assume though,from the look of the name on ESPNSTIs file that this one,just like there's,contains MP41/42 data,which,as far as i can see,no form of video player can play the thing,hence why there's cant be played,meaning,this one we have here is probably not able to be played
РР№! Откровенно РіРѕРІРѕСЂСЏ, РЅРµ совсем понимаю, что это Р·Р° фразы. РњРЅРµ кажется, что кто-то отправил этим, возможно, это поклонник, РЅРѕ СЏ РЅРµ уверена, как СЃ этим работать. Рто напоминает шаблон, Рё СЏ РЅРµ совсем понимаю, как его использовать. Было Р±С‹ Р·РґРѕСЂРѕРІРѕ, если кто-то СЃРјРѕРі Р±С‹ объяснить РјРЅРµ, как правильно это применить. Благодарю! cover point view beginner daughter skin mindset seasonal morning gsljigfdkw thaw chase
iVBORw0KGgoAAANSUhEUgAAAABGAAAgDAAAAWiAAABCAAAA+vCsfAcaSAuGfXVAciFPWbQqopBcJBwQDAABVsvHwPaDACCCJSHaFBcCbOzptAbD8++8NcvSVaQFJoPfjCDjSQbFAVwjQoOfPncXJsOanCVzhSjOqPfnNcbKxmKaNaQiBehQgDAWhYjPfjCMSnBaSayGEAWgPPdQVdSxCFYeGqEAfSgAQnFlApNfhCVzCsAFpBazvfXacHaQcSQQFCFJdPqpPtbCPaQzjrbHazfC//BVGAYPveSgGaEQVeWWaWAWjzpslCPNabQVeyAzofbzcHVsVqiFbAhPBshAgGGHPspSbYaEABGVBdQEQNsoDnApAQQBeQCGHxCbVGcBGKOWCPN8402bvxivBCGYHGeADBqgEADPQZFTKPABVOPANFaDiaQiVBORw0VCGWvPqFCBzhEBaqzgiBxvZhWQJdpSnQBfgSAWhDhGyVzyBdFhYxCyCHcgChChHcuVgUcgUcgCuDQozfgGWgUqDGaRSQbzvQJGPNgjWbWhGzgVzSvCYGWhIrnJc5BbzgYx79BcBxjSBVHBLEQBegQgFWVqIroCpDnEBqarGdWtWstDfFHEPQNFn8zbAhEuS9BchAgFwzbwpWpmDg5vCSQOdlpCmVDYVsvALwQhDgCGVageQoHdgWGyvaQSSlcpJcJavWhzeADhGagFCBKPWlnAjBdHxGGGCGsgAgLfpJcbMfmSbAYdvADAoFHcyChShQjFpWA888BxgAgAfp9nCVaA82VzfAA370BcGa4TGGEQmkOcSWaoqpRnXvXgauQSCFXyGwhQlGfFCzSQBfWtDA9pCnZgSQ+XSCaFdhKaPfkQGfrhGctCHwQLtpLdlARVaGfgARAzrAFCbJflAbAgGaGdQEAhIrpFJfkCmFFJfVeuOqPfWgFAFNxbFXcJdoAoPqlNdGxcHOaoGryCSgAQzrhCsnLaPdkARhQGeYqGSOGPJFOhxhDAhKrpPf78xnBfbQQhRoLqOrkChGGayAhQPfjNcnZvGsiVqOfoJpnGVxvCCVDggsgOaPjrjWjJrIwvYwyOqPtVMxoJfvAvGwGafGwg/XCahWpTbOwpHoLaiFHayVejglCnKdoWkPekhCvVavAhHdoQpNrhGaCafFwyAvSCACAcGkPlfPfnWjDvAhVdhHaiBdgAyGFAahEhAEQlRpBazfhCHVVsvWpJfPBaMxbCCZkKsoSvQgGeyVaOfpCobZjRvHaFetVcvXABrozptjGhHwgEtQGdvAcGwizepJajzfkMcNzvCTsvzxhNejQpKrhGwfDtQcDwA8BdA//2inChU9K40anqOtuCy380qj8r9us9Otja19jthGcg72904jGVVUOw09q0fWhC188fa2uag2WHqg469a0ajgj8ejd84ya920hGCUOeuUwa840O19ah4u26Fq+G370wha3hVsfCahSIr0qjfshahFH9WGJ03N9fhQua2gsuwizo3000rjofjeaaaWbiFqtUeiIq0rkjWisgCFRCIspWo9QgEWfWcFtCTatVaWhHqoHeyaq549afDjXFUOs90w94jCgVCFUaoq02ABCavQ30aq9ibCCFq1us939fadgWfWguTGGCsLwp04iahcGCayI300/gsu930BfVAccEu004bFCaoPejIehUqzhruYwys737914inVCYwoQ0jLfkLcpMdoWp0tou73bahfhFc68W016GscU49T0JhEkOq0o2hy6dhsngkWjTo0wp2Tq56wyjYfgBGdU10hr7YfgSgRq53ia0riJfHwFqr9826UfkKckOawp0478JfuWgyWgYq9r0hCY8w9Q0u37HcGw1903uWc1y9e90dVzxE9au6yFhEu9wizhrjqhgEy995u6f5GwhQhz3g4glCsA8+EucSNVxQOFpL6pSEQZ0x7KTeNWpI0eyds3R46MEsDyxAHUIftf/+1w9x77BlU6PNN4DlY4ckLrUbfoBu6SAPHpVi+goyvveCIEL5377J2CZ5/YuHwpUMXRWRINP8hA8mmJ2MHkrSN4PKgrZBOj+3NKlWXeeLXAQITqBu9/1gDzyS5tYT94gEsyA7OiLM1kCkD1+qwc2PjGUBZEa1IQQPJxXewkEVGWB+lRkN7tUL+ihjAqz0lirSJ4/ub4rmUA8DEuGCAiDAFDmAC1V3OtNv8MXJwxtF8pA0IfLolw6ADyIV38IAEARAfwEJfc6XAiF/47X0G47dT8NdnPyd/egPDZdiQgAACKB/xUcC135X99FsLMRL0VQVXJHz+OmemA8bFYfEFEBJMH6VVbzG2pmieXT1nLa1GQn7Ffg9lMtkDxGU39gKAgJhte9a0fjSbgFqW9HwF180fi7cCY9w9BqiIdhGqu9fIhqcg2UG0JQHDUHWH+DHAIR0A0EJGI0fvAcT16s850FCati0siVnXmoSk0qpLrkLqEhQhjawF17J399azjrh7qjH2u2yag2tGqV2hY1gh2hJ2io836uBckKspPq0wptjHftyF56fjY1y4hGq6EgBqustQfs9PIP+azolLus6dloDOEBNnO8yx7FwPFBWJBh5NMsh7t1HCdHGNiOfnjnvb5VEfeJloFTNM/A8cFOA8nhMB4H3LiwUfgiGd+oHScag839GvgSvY1904jBckFo0rnHqtR7I400wjHqgEfScGsiOq0Heua5qtV36Qu500HccCFYTrt4qfR7003hFjNekWjHgst653gQEgTqXCEggQu9599d0EbQfEtE6fwDnJfnKfiOwjYqa55Faq//DdgAfQRuW5agFSQ840a9djhGagawiiA86gDfaxaGq6at2ga36710aorbQaeAWQEGqbEfYq8490doabrXqy84HqgFe700o5bHhhCgIwiOwiHqHehHqiIeyYqgRAt6490fhR8oGo0CvEcIq9+GdgQgW9GwfFqEfIw0sri8w9surtGqc+GsfWcUw00JfhVvSvQ+DvSha9q0ehXCXaIw9z4uGc6YsHwuQiE9PqkE9DcFAt5atEYqWtQtU3to029thuFZgDIR0WJFWGA2gF740hcWfQhti0add5tvbbvraeuatduuHagGst5GdHbWvGwuQ904hC90aeyWgRWgRWWgaOo9rua8w9E90W0o6cW02iNquzg4t55gDcCYw9Q0svgeO9qzjrhGtFy53hFjkMjwhGqgEuiI1uY46Y3haejoawjsiFu993fb9f9DU0HDBI03HIEFGRID9qDDDDDDDDDDDDDDDDDD3DDDDDDDDDDDDDDDDDDDDDDDDDD80WJTBHAFFAFFFFFFDDDDDDDDDDDDDFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFJWO0EJbCGwiQzegDDDDDDDD+AAAAElFTkSuQmCCwhy doesn't this work9 0
Модельный ряд MacBook охватывает различные уровни производительности и размеры экранов, поэтому каждый может подобрать подходящую конфигурацию.
RCAE;==313, encode:I think your standingAAAAIGZ0eXBpc29tAAACAGlzb21pc28yYXZjMW1wNDEAA
So the whole thing might be a bit "cooked" level of difficulty.
But it also shows that it may, indeed, be a part of an mp4 video file!
AAAAIGZ0eXBpc29tAAACAGlzb21pc28yYXZjMW1wNDEAAB7qbW9vdgAAAGxtdmhkAAAAAAAAAAAA
AAAAAAAD6AAAeSsAAQAAAQAAAAAAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAABAAAAAAAAAAAAAAAA
AABAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAwAABHN0cmFrAAAAXHRraGQAAAADAAAA
AAAAAAAAAAABAAAAAAAAeRgAAAAAAAAAAAAAAAAAAAAAAAEAAAAAAAAAAAAAAAAAAAABAAAAAAAA
So the rest after the thing I told, may actually be file dependant, incredibly so
AAAAIGZ0eXBpc29tAAACAGlzb21pc28yYXZjMW1wNDEAAAA IZnJlZQ
Also apparently known as
... ftypisom....isomiso2avc1mp41....free.
I have tried, via the context of the other mp4 file, to reconstruct our file here, better.
AAAAIGZ0eXBpc29 tAAACAGlzb21pc28yYXZ jMW1wNDEAAAAIZnJl ZQ AAAS1 tZGF 0AAACYgYF// +q3EXpveb ZSLeWLNgg2SPu73gyNjQgLSBjb3JlIDE 0Mi
ftypisom isomiso2avc1mp41 free -mdat - core 142
That's something